RustGPT : Expérience avec Rust + HMTX pour le développement Web
Vous pouvez trouver l'intégralité du code sur GitHub.
Vous pouvez également essayer l'application, j'héberge une version de démonstration ici : rustgpt.bitswired.com.
J'ai plus de 10 ans d'expérience dans les technologies web, mais je suis actuellement un débutant en Rust et j'apprends le langage. Travaillant dans le domaine de l'ingénierie des données/intelligence artificielle, j'utilise intensivement Python (pour manipuler les données et les modèles) et TypeScript/JavaScript (pour construire des applications intégrées à des modèles d'IA).
Bien que mon exposition à des langages comme C, C++, Haskell, Java et Scala ait principalement été académique ou à titre de passe-temps, je me suis senti attiré par Rust. Et pour mieux apprendre Rust, quoi de mieux que de se lancer dans un projet ?
Cela fait un certain temps que je voulais aussi essayer HTMX. C'est donc l'occasion parfaite de plonger dans les eaux rouillées tout en surfant sur la vague HTMX : construisons un clone de ChatGPT avec Rust, HTMX et mon framework de style préféré, TailwindCSS.
C'est déjà au moins mon 4ème clone de ChatGPT avec différentes technologies, car c'est un excellent projet Hello World pour évaluer une pile technologique pour le Web.
En effet, ChatGPT implique :
- L'authentification : les utilisateurs doivent pouvoir s'inscrire, se connecter et avoir des données personnelles
- La base de données : stocker les données des utilisateurs
- Le streaming : implémenter les événements envoyés par le serveur (SSE) pour réaliser un streaming de texte.
Plongeons donc dedans.
Justification de la pile
D'accord, l'ensemble sera :
- Axum pour le serveur web
- Tera pour le templating
- SQLite et SQLx pour la base de données
- HTMX pour l'interactivité
- TailwindCSS pour le style
- Justfile pour organiser les commandes utiles.
Choisir le framework backend (Axum)
Après avoir examiné les frameworks Web en Rust, en particulier Actix et Axum, j'ai penché vers Axum. Bien que je manquais d'expérience préalable, l'approche d'Axum a résonné avec moi. Il offrait des moyens intuitifs de naviguer dans les exemples de code et une mise en œuvre importante des fonctionnalités telles que :
- Routage
- Partage de l'état (comme la pool de bases de données, ...)
- Middleware (par exemple, l'authentification)
- Sérialisation/Désérialisation
- Extraction des paramètres dans les gestionnaires de routes (comme les paramètres de chemin, les chaînes de requête, ...)
- Streaming des réponses (SSE)
- Gestion des erreurs
Choisir le framework de templating (Tera)
Il existe principalement deux bibliothèques de modèles souvent mentionnées dans l'écosystème Rust :
- Askama
- Tera
En bref, les modèles Askama sont compilés statiquement, ce qui signifie que le compilateur détectera les erreurs comme l'oubli de transmettre une variable requise à un modèle. Ils sont également plus rapides grâce à la phase de compilation.
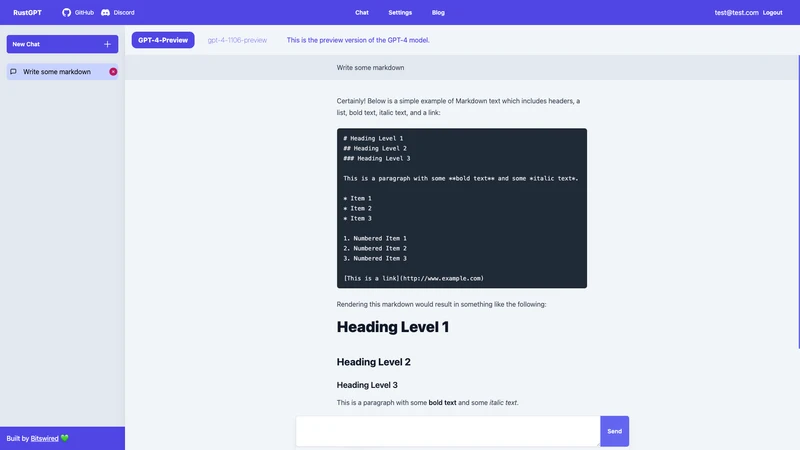
Les modèles Tera ne sont pas analysés statiquement, vous pouvez donc avoir des erreurs d'exécution, cependant ils sont plus flexibles, notamment parce qu'ils supportent des fonctionnalités plus proches de Jinja : vous pouvez définir des macros prenant des paramètres comme des fonctions et les réutiliser comme des composants dans d'autres modèles. Par exemple, voici un "composant HTML" réutilisable pour afficher un message dans l'interface de chat que je peux réutiliser dans d'autres modèles Tera :
{% macro message(variant, text) %}
<div data-variant="{{ variant }}" class="p-4 px-16
data-[variant=ai]:bg-slate-100
data-[variant=ai-sse]:bg-slate-100
data-[variant=human]:bg-slate-200
">
<div class="max-w-[600px] m-auto prose">
{% if variant == "ai-sse" %}
<div id="message-container">
<!-- Les messages seront ajoutés ici -->
</div>
<div id="sse-listener" hx-ext="sse" sse-connect="/chat/{{ chat_id }}/generate" sse-swap="message"
hx-target="#message-container"></div>
{% else %}
{{text | safe}}
{% endif %}
</div>
</div>
{% endmacro input %}Comme vous pouvez le voir, cela prend en paramètre une variante et un texte et les rend en conséquence.
Ensuite, je l'utilise comme suit dans le modèle chat.html:
{% import "components/message.html" as macros %}
...
<div class="flex flex-col h-full w-full overflow-y-auto">
{% if chat_message_pairs %}
{% for pair in chat_message_pairs %}
{{ macros::message(variant="human", text=pair.human_message_html) }}
{% if pair.pair.ai_message %}
{{ macros::message(variant="ai", text=pair.ai_message_html) }}
{% else %}
{{ macros::message(variant="ai-sse", text="") }}
{% endif %}
{% endfor %}
{% endif %}
<div id="new-message"></div>
<div class="mt-[200px]"></div>
</div>
...C'est aussi simple que macros::message(variant="ai", text=pair.ai_message_html) d'utiliser le composant.
Pas besoin d'un framework JS pour ajouter des composants réutilisables à votre application 😉.
Choisir un framework de style (TailwindCSS)
Ici, je n'ai pas grand-chose à dire, mon esprit était déjà fait. J'aime TailwindCSS principalement parce que je n'ai pas besoin de gérer une multitude de fichiers CSS supplémentaires (tout est intégré dans mon HTML) et je n'ai pas à trouver des noms (c'est pénible de nommer des classes en CSS pour la réutilisation et la sémantique, Tailwind résout cela magnifiquement).
Une chose que j'ai découvert, cependant, c'est Standalone Tailwind qui est un exécutable autonome : vous pouvez exécuter TailwindCSS sans avoir besoin d'installer NodeJS et NPM. C'est cool car je veux éviter de mélanger ma pile Rust étincelante avec des outils JavaScript car je n'écrirai pas une seule ligne de JS dans ce projet.
Choisir la base de données et "utiliser un ORM ou non ?"
J'ai choisi SQLite presque à chaque fois pour les nouveaux projets :
- C'est super pratique : la base de données vit dans un seul fichier. Besoin de déboguer en production ? Il suffit de copier le fichier sur votre machine locale et de déboguer. Besoin de tester ? Créez simplement la base de données en mémoire.
- C'est rapide : la base de données vit dans le même processus que votre code, c'est aussi proche que possible.
- Cela évolue assez bien même avec des écritures concurrentes en utilisant le mode WAL.
- De plus, c'est SQL, ce qui signifie une intégrité et des transactions solides des données.
Pour gérer les opérations de base de données, j'ai utilisé une bibliothèque Rust appelée SQLx. Elle gère les migrations, la création de la base de données et, plus important encore, la vérification des requêtes lors de la compilation ! Wow, j'adore cette fonctionnalité. Vous pouvez voir dans l'éditeur de code si vos requêtes sont valides, et le code ne se compilera pas si vous faites une erreur.
Cela fonctionne grâce à des macros procédurales en Rust qui permettent à la bibliothèque de se connecter à la base de données pour vérifier votre demande lors de la compilation. Et je peux vous dire que cela évite des tonnes d'erreurs !
J'adore aussi le fait qu'il vous donne un accès direct à la base de données et que ce n'est pas un ORM. Je ne vais pas rentrer dans le débat ici, mais j'ai tendance à préférer ne pas utiliser un ORM. SQL brut + sérialisation avec Serde dans les structures Rust vous permettront d'aller loin et vous contrôlez entièrement les requêtes. Les ORM peuvent être pénibles lorsqu'il s'agit de travailler avec des jointures, ou ils peuvent parfois produire des requêtes étranges qui sont sous-optimales ( je te regarde, Prisma, qui effectue des requêtes supplémentaires pour les relations au lieu de les joindre lien vers un problème).
Ajouter de l'interactivité (HTMX)
Ici, aucun argument spécifique pour ce choix, sauf que je voulais donner à HTMX une véritable chance depuis un certain temps. Ce qui me séduit le plus dans cette technologie, c'est que je peux choisir mon langage préféré pour construire une application web interactive sans avoir besoin de quitter le domaine du backend. Ainsi, je n'ai pas besoin de dupliquer la gestion de l'état dans le backend et le frontend comme vous le faites généralement avec des frameworks tels que React (par exemple en utilisant des outils tels que React Query pour synchroniser les états du serveur et du client). Je n'ai pas besoin de partager des interfaces entre deux environnements pour les transferts de données. Et je n'ai pas besoin d'envoyer un énorme bundle JavaScript au client (HTMX ne fait que 1,3 ko minifié + gzipé).
Organisation des commandes (Juste)
J'ai découvert récemment Just en tant qu'exécutant de commandes et de tâches pratique.
- init: Installe les dépendances nécessaires (
cargo-watchetsqlx-cli). - dev-server: Surveille les changements dans des répertoires/fichiers spécifiques et redémarre le serveur en conséquence.
- dev-tailwind: Surveille les changements dans le fichier
input.csset compile TailwindCSS en conséquence. - build-server: Construit le serveur en mode release.
- build-tailwind: Minifie TailwindCSS.
- db-migrate: Exécute les migrations de base de données en utilisant SQLx.
- db-reset: Réinitialise la base de données, en la supprimant et en la recréant tout en exécutant les migrations et en ajoutant des données.
- dev: Exécute simultanément les tâches
dev-tailwindetdev-server, gérant leurs processus et gérant leur terminaison.
Ce setup optimise le flux de développement, automatisant diverses tâches telles que le rechargement du serveur, la compilation CSS et les opérations de base de données.
Rouille 💚
Tout d'abord, j'adore coder en Rust et créer une application web a été une expérience amusante.
Je m'habitue au compilateur Rust et au changement mental nécessaire pour coder en Rust : l'emprunt, les macros procédurales, les références mutables vs non mutables, les traits...
Je ne vais pas mentir, cela demande de la diligence et parfois ça peut être difficile de faire fonctionner un morceau de code, mais dans l'ensemble, ça va, surtout si vous avez déjà de l'expérience avec d'autres langages compilés.
J'ai remarqué qu'en Rust, je passe plus de temps dans mon éditeur de code pour faire fonctionner le code, mais quand il est compilé, il fonctionne généralement comme prévu et est exempt de problèmes d'exécution. Alors qu'en Python et TypeScript, j'écris très vite mais je passe plus de temps à déboguer des problèmes d'exécution.
Et je peux vous dire que je préfère certainement faire en sorte que le code se compile plutôt que de déboguer à l'exécution 😅.
Aussi, quelque chose que j'adore en Rust, c'est la gestion des erreurs avec le type Result : c'est cool d'avoir des fonctions qui peuvent potentiellement échouer en renvoyant un Result ! Cela vous oblige à traiter le résultat en gérant l'erreur ou en déballant, ce qui peut provoquer des problèmes d'exécution, mais au moins vous le faites délibérément. Combinez cela avec l'opérateur ? et c'est génial.
Le système de traits et l'absence d'héritage sont également des fonctionnalités que j'adore particulièrement.
Je vais vous donner un exemple de difficulté pour moi en tant que débutant en Rust :
pub async fn chat_generate(
Extension(current_user): Extension<Option<User>>,
Path(chat_id): Path<i64>,
State(state): State<Arc<AppState>>,
) -> Result<Sse<impl tokio_stream::Stream<Item = Result<Event, axum::Error>>>, ChatError> {
let chat_message_pairs = state.chat_repo.retrieve_chat(chat_id).await.unwrap();
let key = current_user
.unwrap()
.openai_api_key
.unwrap_or(String::new());
match list_engines(&key).await {
Ok(_res) => {}
Err(_) => {
return Err(ChatError::InvalidAPIKey);
}
};
let lat_message_id = chat_message_pairs.last().unwrap().id;
// Créez un canal pour envoyer les événements SSE
let (sender, receiver) = mpsc::channel::<Result<GenerationEvent, axum::Error>>(10);
// Génère les événements SSE et les envoie dans le canal
tokio::spawn(async move {
// Appelez votre fonction existante pour commencer à générer des événements
if let Err(e) = generate_sse_stream(
&key,
&chat_message_pairs[0].model.clone(),
chat_message_pairs,
sender,
)
.await
{
eprintln!("Erreur lors de la génération du flux SSE : {:?}", e);
}
});
// Convertit le récepteur en un flux pouvant être utilisé par Sse
// let event_stream = ReceiverStream::new(receiver);
let state_clone = Arc::clone(&state);
let receiver_stream = ReceiverStream::new(receiver);
let initial_state = (receiver_stream, String::new()); // État initial avec un accumulateur vide
let event_stream = stream::unfold(initial_state, move |(mut rc, mut accumulated)| {
let state_clone = Arc::clone(&state_clone); // Clonez l'Arc ici
async move {
match rc.next().await {
Some(Ok(event)) => {
// Traite l'événement
match event {
GenerationEvent::Text(text) => {
accumulated.push_str(&text);
// Renvoie les données accumulées en tant que partie de l'événement SSE
let html =
comrak::markdown_to_html(&accumulated, &comrak::Options::default());
let s = format!(r##"<div>{}<div>"##, html);
Some((Ok(Event::default().data(s)), (rc, accumulated)))
}
GenerationEvent::End(text) => {
println!("accumulated: {:?}", accumulated);
state_clone
.chat_repo
.add_ai_message_to_pair(lat_message_id, &accumulated)
.await
.unwrap();
let html =
comrak::markdown_to_html(&accumulated, &comrak::Options::default());
let s = format!(
r##"<div hx-swap-oob="outerHTML:#message-container">{}</div>"##,
html
);
// ajoute s au texte
let ss = format!("{}\n{}", text, s);
println!("ss: {}", ss);
// accumulated.push_str(&ss);
// Gère la fin d'une séquence, réinitialise éventuellement l'accumulateur si nécessaire
Some((Ok(Event::default().data(ss)), (rc, String::new())))
} // ... gère d'autres types d'événements si nécessaire ...
}
}
Some(Err(e)) => {
// Gère l'erreur sans modifier l'accumulateur
Some((Err(axum::Error::new(e)), (rc, accumulated)))
}
None => None, // Lorsque le flux de réception se termine, termine le flux
}
}
});
Ok(Sse::new(event_stream))
}Ici, l'idée était d'accumuler et de traiter le flux créé par la fonction generate_sse_stream. Elle fait appel à l'API OpenAI en mode streaming et renvoie un flux de génération de texte. Maintenant, dans mon gestionnaire de route, je souhaite traiter ce flux pour l'analyser en Markdown vers HTML et l'accumuler afin de pouvoir enregistrer l'ensemble du message dans la base de données lorsque la génération est terminée.
J'ai rencontré quelques difficultés pour le faire, car j'ai besoin de mapper un flux tout en accumulant une valeur et ce, tout en utilisant des fonctions asynchrones (pour l'appel à la base de données).
Mais ce n'est pas tout, car j'ai également besoin d'envoyer chaque morceau au fur et à mesure que je les traite. Donc, pour résumer, voici ce qui se passe pour chaque morceau provenant du flux OpenAI :
- Accumuler le morceau dans une variable
- Le transformer en HTML avec un processeur de Markdown
- Vérifier si le flux est terminé, et si c'est le cas, faire un appel à la base de données
- Envoyer le Markdown accumulé actuel à l'utilisateur via SSE
- Répéter...
Au final, j'ai réussi à le faire fonctionner. Cependant, je ne peux pas vous dire que j'ai utilisé la meilleure méthode possible, car je suis un novice en Rust.
Mon défi était d'abord d'identifier le besoin de la fonction 'unfold', qui permet de traiter de manière asynchrone un flux tout en accumulant des valeurs et en générant de nouveaux éléments en temps réel, sans traiter l'ensemble du flux en une seule fois. Ensuite, j'ai dû gérer les déplacements correctement pour satisfaire le vérificateur d'emprunt, ce qui a donné l'implémentation suivante :
Laissez l'événement_stream = stream::unfold(état_initial, move |(mut rc, mut accumulé)| {
Laissé état_clone = Arc::clone(&état_clone); // Clonez l'Arc ici
async move {
Correspondre à rc.next().await {
...HTMX 💚
J'ai utilisé HTMX plus l'extension SSE pour gérer les flux de données.
Discutons de la mise en œuvre des différentes fonctionnalités interactives de l'application, cela vous donnera peut-être des idées.
Diffusion en temps réel avec SSE

L'extension SSE appelle le point de terminaison dont nous avons discuté dans la section précédente sur Rust.
Translate the following content to French, here is the key associated to this content in the CRM: content.content.29.code (answer like an api, return only the translation, nothing else):
{% macro message(variant, text) %}
<div data-variant="{{ variant }}" class="p-4 px-16
data-[variant=ai]:bg-slate-100
data-[variant=ai-sse]:bg-slate-100
data-[variant=human]:bg-slate-200
">
<div class="max-w-[600px] m-auto prose">
{% if variant == "ai-sse" %}
<div id="message-container">
<!-- Messages will be appended here -->
</div>
<div id="sse-listener" hx-ext="sse" sse-connect="/chat/{{ chat_id }}/generate" sse-swap="message"
hx-target="#message-container"></div>
{% else %}
{{text | safe}}
{% endif %}
</div>
</div>
{% endmacro input %}
{% macro message(variant, text) %}
<div data-variant="{{ variant }}" class="p-4 px-16
data-[variant=ai]:bg-slate-100
data-[variant=ai-sse]:bg-slate-100
data-[variant=human]:bg-slate-200
">
<div class="max-w-[600px] m-auto prose">
{% if variant == "ai-sse" %}
<div id="message-container">
<!-- Les messages seront ajoutés ici -->
</div>
<div id="sse-listener" hx-ext="sse" sse-connect="/chat/{{ chat_id }}/generate" sse-swap="message"
hx-target="#message-container"></div>
{% else %}
{{text | safe}}
{% endif %}
</div>
</div>
{% endmacro input %}Je crée d'abord un conteneur de message pour stocker le message.
<div id="message-container">
<!-- Les messages seront ajoutés ici -->
</div>Ensuite, la div suivante se connecte directement à l'endpoint SSE.
<div id="sse-listener" hx-ext="sse" sse-connect="/chat/{{ chat_id }}/generate" sse-swap="message"
hx-target="#message-container"></div>En le faisant, il échangera les messages HTML qu'il reçoit dans #message-container.
Enfin, du côté du serveur, lorsque le flux est terminé, nous remplaçons #sse-listener par une division vide. C'est un moyen d'arrêter la source d'événements, sinon le navigateur continue d'essayer de se reconnecter, déclenchant une génération supplémentaire non souhaitée.
<div hx-swap-oob="outerHTML:#message-container">{}</div>Nous utilisons ici une mise à jour hors bande, ce qui signifie que nous remplaçons un élément à un emplacement arbitraire sur le site web.
Supprimer les chats
Ici, c'est simple, nous avons
<a class="hidden group-hover:flex text-pink-700 absolute inset-y-0 right-0 justify-center items-center" hx-delete="/chat/{{ chat.id }}" hx-target="#chat-{{ chat.id }}" hx-swap="outerHTML">
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" fill="currentColor" class="w-6 h-6">
<path fill-rule="evenodd" d="M12 2.25c-5.385 0-9.75 4.365-9.75 9.75s4.365 9.75 9.75 9.75 9.75-4.365 9.75-9.75S17.385 2.25 12 2.25zm-1.72 6.97a.75.75 0 10-1.06 1.06L10.94 12l-1.72 1.72a.75.75 0 101.06 1.06L12 13.06l1.72 1.72a.75.75 0 101.06-1.06L13.06 12l1.72-1.72a.75.75 0 10-1.06-1.06L12 10.94l-1.72-1.72z" clip-rule="evenodd" />
</svg>
</a>
Créez un nouveau chat
Celle-ci est simple mais intéressante car elle montre un autre grand pouvoir que vous offre HTMX : vous pouvez combiner des données provenant de plusieurs éléments de saisie situés dans des formulaires et des emplacements de page complètement différents en utilisant l'attribut hx-include.
<button type="submit"
class="py-3 px-4 inline-flex flex-shrink-0 justify-center items-center gap-2 rounded-r-md border border-transparent font-semibold bg-indigo-500 text-white hover:bg-indigo-600 focus:z-10 focus:outline-none focus:ring-2 focus:ring-indigo-500 transition-all text-sm"
hx-post="/chat" hx-include="[name='message'], [name='model']">
Créer
</button>Lorsque vous créez une nouvelle discussion dans RustGPT, vous devez spécifier un modèle et un premier message humain. Cependant, ces informations se trouvent à des endroits différents sur la page, donc j'ai demandé à HTMX de rassembler les données lors de l'envoi à l'endpoint qui crée la nouvelle discussion avec un sélecteur de requête hx-include="[name='message'], [name='model']".
C'est incroyable de voir à quel point les fonctionnalités interactives complexes peuvent être réalisées de manière déclarative avec HTMX !
Ajouter de nouveaux messages à la discussion
Un autre exemple est de continuer à discuter après le premier message. Comme vous pouvez le voir ici, lorsque vous envoyez un nouveau message après la réponse initiale de l'IA, je vais échanger l'élément #new-message avec le contenu que vous avez posté.
<form class="max-w-[800px] mx-auto" method="post" hx-post="/chat/{{ chat_id }}/message/add" hx-target="#new-message" hx-swap="outerHTML">
<div class="shadow-lg pb-2 backdrop-blur-lg">
<label for="hs-trailing-button-add-on" class="sr-only">Etiquette</label>
<div class="flex rounded-md shadow-sm">
<textarea name="message" type="text" id="hs-trailing-button-add-on" name="hs-trailing-button-add-on" class="p-4 block w-full border-gray-200 shadow-sm rounded-l-md text-sm focus:z-10 focus:border-indigo-500 focus:ring-indigo-500"></textarea>
<button type="submit" class="py-3 px-4 inline-flex flex-shrink-0 justify-center items-center gap-2 rounded-r-md border border-transparent font-semibold bg-indigo-500 text-white hover:bg-indigo-600 focus:z-10 focus:outline-none focus:ring-2 focus:ring-indigo-500 transition-all text-sm">
Envoyer
</button>
</div>
</div>
</form><div class="flex flex-col h-full w-full overflow-y-auto">
{% if chat_message_pairs %}
{% for pair in chat_message_pairs %}
{{ macros::message(variant="human", text=pair.human_message_html) }}
{% if pair.pair.ai_message %}
{{ macros::message(variant="ai", text=pair.ai_message_html) }}
{% else %}
{{ macros::message(variant="ai-sse", text="") }}
{% endif %}
{% endfor %}
{% endif %}
<div id="new-message"></div>
<div class="mt-[200px]"></div>
</div>Ici, vous pouvez voir qu'après avoir affiché tous les messages, j'ajoute un espace réservé vide <div id="new-message"></div>. Cela permet à HTMX de toujours savoir où ajouter un nouveau message. Ensuite, le serveur répond avec :
Traduisez le contenu suivant en français, voici la clé associée à ce contenu dans le CRM: content.content.49.code (répondez comme une api, ne retournez que la traduction, rien d'autre):
{% import "components/message.html" as macros %}
{{ macros::message(variant="human", text=human_message) }}
{{ macros::message(variant="ai-sse", text="") }}
<div id="new-message"></div>Ici, nous remplaçons la div par le message humain que vous venez de poster, puis un message ai-voir qui déclenche la génération SSE dès qu'il est rendu dans le document.
Et n'oubliez pas d'ajouter de nouveau un espace réservé #new-message pour gérer le prochain message que vous allez poster.
Si simple mais permettant une interactivité complexe. C'est pourquoi j'aime beaucoup HTMX.
Regarder vers l'avenir
Rust + HTMX est une combinaison géniale alliant la puissance du langage Rust avec une interactivité déclarative.
Je vais certainement envisager cette combinaison pour mes projets futurs, en exploitant Axum pour le serveur web que j'ai trouvé particulièrement puissant.
J'ai l'intention de créer un référentiel de modèles ou un modèle de départ pour la pile utilisée dans ce référentiel : Rust + Axum + Tera + SQLx + Tailwind + Just.
Je veux également essayer sérieusement le framework Leptos.
Et bien sûr, continuer à apprendre et à pratiquer Rust 💚.
J'aimerais avoir votre avis sur cette pile, la considéreriez-vous pour votre projet futur ? Et n'hésitez pas à me faire part de vos suggestions ou à m'apprendre quelques astuces Rust sur le référentiel.
Joyeuse programmation en Rust.