Bitsletter #10: ML Alerts, Secure Web Cookies & Google's C++ Rival

🧠 ML Tip: Use simple alerting tools (Slack, Telegram, ...)
Machine learning is a trial and error process. You do many experiments with different settings (pre-processing, models, post-processing, hyper-parameters, ...) to find the best solution for your problem.
Training at the heart of every experiment: you need to fit a model before evaluating based on a metric. But, as we use bigger and bigger datasets with more complex models, the training process takes significant time to complete, even with modern accelerators such as GPUs.
It can be frustrating if your training scripts fail in the middle of a long-running experiment, and you realize it potentially many hours later. The faster you identify an issue, the less time you will lose: you can fix it fast, re-launch the script, or investigate deeper a severe problem. Nowadays, we all have smartphones and messaging applications with real-time notifications. E.g., Telegram, Slack, Discord, ...
These applications have developer kits, so you can push messages to a channel programmatically. You can monitor the state of your training by simply sending messages to you or a group channel if something bad happens, or hopefully, notify if your experiment is completed successfully. Use libraries such as telegram_send, or the Slack Python SDK to bring peace of mind to you and your team.
🌐 Web Tip: Using HTTP-only cookies, how to determine if a user logged in client-side?
To authenticate and authorize users on your web applications, you need to identify them on every query they make to your backend servers. To do so, you need a token associated with each request. Common ways to proceed are sessions or JWTs(JSON Web Tokens).
A typical workflow is the following:
👉🏽 Somebody hits the login endpoint of your API.
👉🏽 You very the credentials, and if correct, you send back a token uniquely identifying the user.
👉🏽 The client receives the token and stores it in the local storage. Then on every future request, attaches the token to the request headers so the backend can determine who is the user making requests.
🚨 However, it has drawbacks since the local storage can suffer JavaScript attacks.
An alternative is to use HTTP-only cookies to safely store the token on the client-side, without any access possible from JavaScript. The browser sends the cookie on every future request and forbids any code to access the cookie. It's great for security, but since you can't access the cookie in the code, how do you determine if the user is logged in client-side?
The simplest solution is to expose a route in your API that returns the user profile when queried by an authenticated user. Something like /me. Then when your application mounts, query the /me route; if you receive the profile, you're logged in. Now intercepts any 401 error (unauthenticated) from your client requests, and set your applications state to unauthenticated. Ta-da! You now have a fully-fledged authentication system based on HTTP-only cookies.
👩🔬 Research Paper: Prune Once for All: Sparse Pre-Trained Language Models
Transformer-based models showed impressive results in natural language processing tasks. However, they are computationally inefficient and hard to deploy in production. A way to alleviate this problem is to use compression techniques to make to model smaller and reduce the computation complexity.
There are multiple ways to do it. Knowledge distillation: it trains a student network (usually smaller than the teacher) to reproduce the behavior of a teacher model. To reproduce the predictions from the teacher model, the soft cross-entropy loss is used between the student and teacher output probabilities.
Weight pruning: it's a process that forces some weights of a neural network to be zero. It can be unstructured where individual weights are pruned or structured where groups of weights (channels, blocks, ...) are set to zero. Weight pruning makes the network sparse, reducing the computation time and space requirements.
Quantization: we use floating-point numbers for neural networks, usually 32 bits precision. Quantization reduces the precision (16 bits, 8 bits, ...) while preserving as much as possible accuracy: the resulting network can be significantly smaller.
Sparse Pre-Trained Language Models leverage these different techniques to reach a surprising compression level while maintaining most of the accuracy on a wide range of tasks. Furthermore, they show how to compress the sparse models’ weights to 8bit precision using quantization-aware training.
The result is a sparse pre-trained BERT-Large fine-tuned on SQuADv1.1 and quantized to 8bit, achieving a compression ratio of 40X for the encoder with less than 1% accuracy loss. 🚀 This is an incredible result. The paper is short and well explained, definitely worth reading.
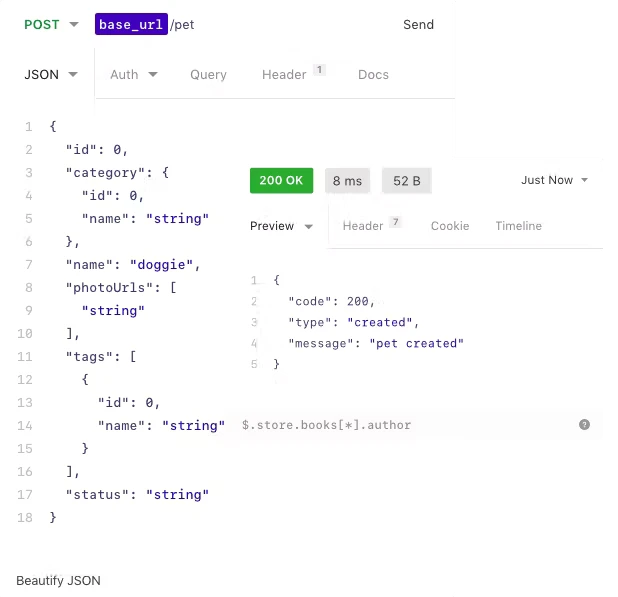
🛠 Tool: Use Insomnia to easily debug and tests your API
Insomnia is a tool to streamline your API development process, from testing with a feature-rich UI client to testing and even building API pipelines. You can even save the configuration of the client and share it with other developers so everybody can use predefined tests queries to invoke the API.
I recently used it in one project where I built an API with Cloudflare Workers. It saved me some time, and I recommend it if you work on APIs. 🚀
Give it a try.
📰 News
BERT-Large (346M params) accuracy with faster inference than DistilBERT (66M) params
Is that even possible?
Yes, it is 🤯.
Researchers partnered with Intel Labs to use cutting-edge sparsification and quantization techniques from the paper "Prune Once for All: Sparse Pre-Trained Language Models". They also used the DeepSparse Engine, an inference engine leveraging sparsity to achieve GPU-class performance on CPUs.
Google working on a C++ replacement: Carbon
Google is working on a C++ replacement, the Carbon language. IT aims to be 100% interoperable with existing C++ programs, while providing modern language features to better fit the needs of developers. It's based on LLVM.