Bitsletter #5: ONNX Unleashed, Tackling Web Waterfalls & Vision Transformers

🧠 ML Tip: Model interoperability and hardware access with ONNX
Nowadays, AI models are used in a variety of computational contexts: embedded systems, powerful GPU stations, CPU, web browsers, ... We need specific deployment targets to support these use cases. But it is daunting to deal with all this complexity when you've just finished developing a model in your favorite framework (PyTorch ^^). 😰
ONNX stands for Open Neural Network Exchange. It defines a common set of building blocks for machine learning and deep learning, as well as a common file format to standardize the models' graph definition. It allows you to develop models with multiple frameworks and tools, while exporting in a common open source format.
It brings 2 considerable benefits:
1️⃣ Interoperability: ease research and development with your favorite framework (PyTorch, TensorFlow, MXNet, Chainer, ...) without sacrificing your deployment options. All these frameworks support exporting to ONNX. Escape framework lock-in.
2️⃣ Hardware access: from the exported ONNX model, you can access a variety of optimized runtimes with access to many hardware accelerators for inference (Habana AI processors, NVIDIA, OpenVINO, deepC, ...)
⚡️Not only ONNX runtimes offer a great inference performance in a variety of contexts (CPU, edge computing, GPU, ...) but you can also apply optimization to the ONNX exported model, such as graph simplification, quantization, ...
🌐 Web Tip: Avoid network waterfalls with SSR
Network waterfalls happen when data fetching occurs in a sequence in instead of concurrently. It’s a common problem with modern frontend framework where you can declare data fetching at the component level.
Let’s say you have 3 components A B and C nested as follows:
If data fetching is declared at the component level for each component: We start to see the waterfall: A, B and C will appear sequentially, waiting for their data fetching one after the other. It results in a bad user experience. The UI feels laggy.
Server Side Rendering (SSR) is a great solution to this problem. The UI makes a query to the backend, then you fetch the data for all components on the server, you render the UI and send it back to the client. The user receives a web page which render instantly without waterfalls.
Frameworks like Remix allow you to simply leverage SSR to deliver blazing fast UI without the waterfall hell.
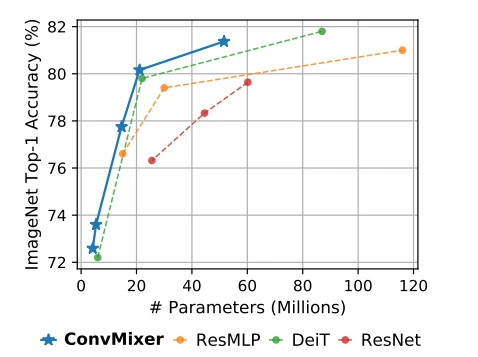
👩🔬 Research Paper: Patches Are All You Need?
Convolutional neural networks dominated vision tasks for many years. Recently, Transformers based architecture are gaining traction and they were applied successfully to vision tasks, especially with the Vision Transformer (ViT). They even outperformed convolutional networks in certain settings. In the paper Patches Are All You Need? the authors explore whether the success of the ViT is due to the Transformer architecture or the use of patches as the input representation.
They introduce a model, the ConvMixer. It’s a patch embedding layer followed by multiple applications of a fully-convolutional block. Interestingly, this simple approach achieved better results than the Transformer based Data-Efficient Image Transformers (DeiT) or the traditional ResNet. It suggests that the success of transformers on vision tasks at least partly comes from the patch based representation of the input and not solely the Transformer architecture.
🛠 Tool: PyAutoGUI, desktop automation
PyAutoGUI empowers your Python scripts with mouse and keyboard control to automate interactions with other applications. It works on Windows, macOS and Linux. Repeating the same tasks over and over can be boring especially as a developer, knowing the automation power at your fingertips.
With PyAutoGUI you can easily automate complex workflows, like data entry in GUI based software, tasks that necessitate interactions with multiple applications, … Even a few minutes a day can be a lot a few years down the line.
📰 News
PyTorch now accelerated on Mac M1
PyTorch collaborated with the Metal engineering team at Apple to support GPU-accelerated training on Mac M1. Before, PyTorch only leveraged CPU on Mac but PyTorch v1.12 release will introduce the possibility to take advantage of Apple silicon for a great jump in performance.
TypeScript 4.7 is out
TypeScript 4.7 is out with many new features. We get ECMAScript module support for Node.js, improved organize import, improved function inference in objects and methods, the stable target at node16 (since node12 is losing support), type in package.json to control wether .js files are interpreted as ES modules or CommonJS, … and many more. Jump ahead and update 🚀.