Bitsletter #6: Achieving Reproducible ML, Web Decoupling, and Hyperbolic Embeddings

🧠 ML Tip: Experiment tracking is not enough, you need to track code and data versions
The value of a machine learning projects falls drastically if it’s not reproducible. Have you ever experienced the unpleasant feeling improving your models, but could not reproduce the result days or weeks later 😅. It may happens because of a different seed, slightly different pre-processing, someone changing the data you relied on, … you name it.
To achieve complete reproducibility, you not only have to track the experiments outcomes (metrics, …) but also the code and the data used during the experiment. Indeed, if the code changes and you try to launch the same script used in an experiment you will likely have different results. The same happens if the data changed during the course of the project.
It sounds like common sense, but in practice it’s that simple to set up. Fortunately there exists tools to help us tracking the experiments, data and code at the same time. Data Version Control (DVC) is a tool for reproducible Data Science:
- Version control the entire machine learning project including models, data sets and intermediate files.
- Connect with Amazon S3, Azure Blob Storage, Google Cloud Storage, SSH, …
- Track the experiments using Git branches and use automatic metric-tracking
- Deploy lightweight ML pipelines as first-class citizen
🌐 Web Tip: Decouple data and presentation
Web applications has two essential parts: the style and the content. It’s easy to couple both when you’re starting a new project, since it’s the quickest and simplest way to go: let’s say you have a blog, you can write HTML/CSS files with your content directly embedded into the code: the title, the body, …
However you will quickly encounter a few pain points:
- Every time you need to update the content, you have to edit code files
- You’re tied to the framework that you picked (either React, Vue, Svelte, raw HTML/CSS, …)
- Editing content in a code editor is not the best experience, it’s much better with a rich text editor
- Coding and testing the presentation is trickier since the application structure and styling is coupled with the content
Instead, you should decouple the content from the presentation entirely.
The best way is to use a headless Content Management System (CMS) such as Strapi: you write the content in the CMS, fetch it using the CMS API, and render it into your application. It’s called a headless CMS since it has nothing to do with presentation, it only handles the content creation and delivery over an API.
Following this strategy has many advantages:
- You write your content once and publish everywhere (thanks to the API)
- You can change the presentational framework easily
- You can edit content without editing the application code files
👩🔬 Research Paper: Poincare Embeddings for Learning Hierarchical Representations
Learning good representations for your data plays a determinant role in the success of your models.
To cite a few examples:
- Word2Vec embeddings
- Google Imagen use text embedding from a large language model to generate photo-realistic images from text descriptions
Most techniques learn embeddings in Euclidean vector space. But it might be suboptimal. Data often exhibits a hierarchical structure, but Euclidean spaces do not account for this property.
In Poincare Embeddings for Learning Hierarchical Representations the authors introduce an approach to learn embeddings in an n-dimensinoal Poincare ball (which is an hyperbolic space). Such embeddings should better capture hierarchy and similarity.
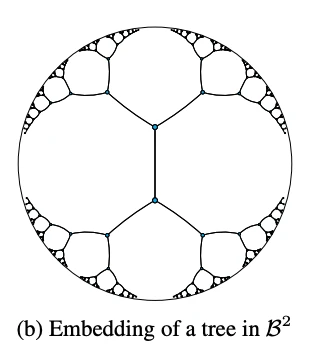
They benchmark their approach on different datasetd with hierarchical properties such as taxonomies (WORDNET noun hierarchies) and network for link predictions. The paper shows significative improvements compared to other traditional approaches. Hyperbolic geometry seems to have a great potential to capture relationships which are tricky to get in other geometries such as Euclidean spaces. Give it a try next time you deal with hierarchical data.
🛠 Tool: Polars, multi-threaded dataframes in Rust with Python bindings
If you worked on data analysis with Python, you most likely used Pandas at some point. It’s one the most popular libraries for data analysis and manipulations. However, Pandas is not multi-threaded by default. If you work with big dataset, common operations such as applying functions, grouping by some columns, … will run on a single CPU. It’s frustrating, since almost all computers nowadays have multicore capabilities.
One solution is to break yourself the dataframe in smaller chunks and use Python multiprocessing to alleviate the issue. However it requires some additional work, and Python mutliprocessing relies on os.fork which can blow up your memory in some cases.
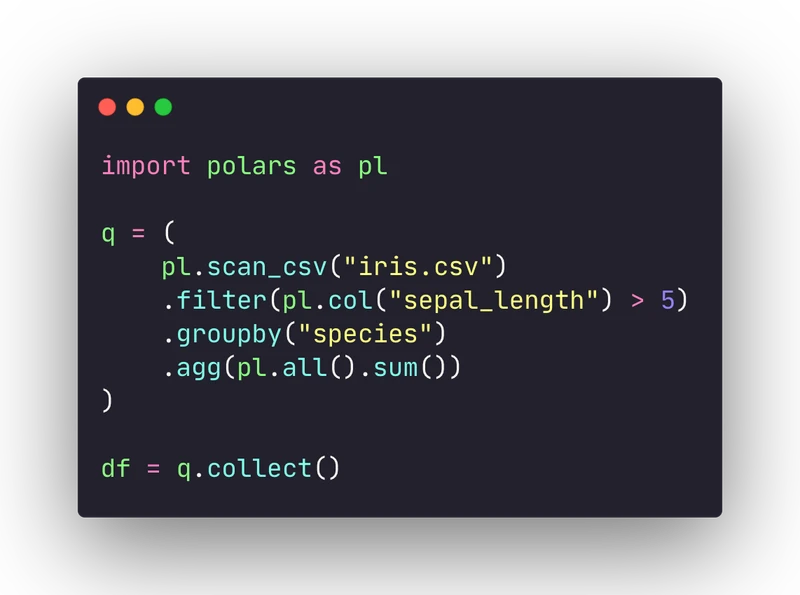
Polars is a dataframe library written in Rust with Python bindings. It is multi-threaded by default and includes a query optimizer (similar to how SQL works) to optimize the computations based on the sequence of operations you want to perform.
It has many compelling features:
📰 News
Native compilation with Wasmer 2.3
Wasmer is a WebAssembly runtime. It allows lightweight containers to run on any platform: Desktop, Cloud, Edge, IoT devices, …
With the new 2.3 release, Wasmer now compiles to WASM/WASI (WebAssembly System Interface) which enables native compilation exclusively in WebAssembly. A major 3.0 release is on the way.
Hallucinating images from text for better translations
For humans, language and visual representations are closely related. If we ear a word, we almost instantly visualize what it represents. What if an AI could have a similar capability? VALHALLA is a machine learning method which “hallucinate” an image from written words. Then uses it to translate the text into another language. Interestingly, this process seems to improve the quality of the translation.