Bitsletter #2: The Power of Data Centric ML & Web Vital Enhancements

🧠 ML Tip: Follow the Data Centric approach when possible
There are two main approaches when you develop machine learning solutions:
- Model centric: the data is locked, you improve the models to get better results
- Data centric: the model is locked, you improve the data to get better results.
As research progresses, the state of the art gets amazingly good in a multitude of tasks. Developing your own model, at your own cost brings diminishing rewards ...
I’m the first tempted to build model from scratch, because it’s fun and educationally important. However, to deliver the highest value, in the shortest time span, it’s not a great approach. How much time did it take for entire teams to build these SOTA models? Is it likely I will beat them in a short amount of time? Do I have the computing resources and enough data to train a huge model from scratch? Realistically not (in many cases).
Let’s introduce another framework:
In this framework the focus is on data. You spend much less time modeling, and much more cleaning, labeling, gathering and preparing data. You leverage the best models available, usually their open source implementation (in your favorite framework), and focus your effort on data quality and quantity.
🌐 Web Tip: Improve web vital metrics with lazy loading
Web vitals are group of metrics to measure the quality of the user experience for web applications. The core metrics are:
👉🏽 Largest Content Paint (LCP): measures loading performance.
👉🏽 First Input Delay (FID): measures interactivity.
👉🏽 Cumulative Layout Shift (CLS): measures visual stability.
A good user experience happens below 2.5 seconds LCP, 100 ms FID and 0.1 CLS: these are guidelines number provided by Google.
If you develop a web application, you now have access to many great JavaScript frameworks: React, Vue, Angular, ... and a myriad of JavaScript libraries thanks to npm and module bundlers.
But it comes at a price ... the size of your application increases.
You might think that powerful computers and high-speed internet alleviates these issues. However an important number of users are still on slow internet connections like 3G and below (e.g in poor countries, ...).
A simple solution to control the web vital metrics of your app is to use lazy loading. The idea is simple, you don’t need to ship the code to render elements outside of the application viewport: since the user doesn’t see them, you should not spend resources on them. The initial load time, interactivity and stability will improve, and as the user navigates your app, you progressively load the required JS code. All Modern frameworks supports lazy loading, start using it to improve user experience.
👩🔬 Research Paper: data2vec, A General Framework for Self-supervised Learning in Speech, Vision and Language
Self-supervised learning is a hot research topic in machine learning. Yan LeCun, chief scientist at Meta, is convinced that it’s a key component to improve deep learning models:
In a few words, it’s a kind of unsupervised learning where the data itself provides supervision. For instance you can pre-train a computer vision model on images without labels: you mask the image randomly and train the model to predict the missing area. Doing so you expect that the model will learn a meaningful representation of the data. Since it is simpler to gather unlabelled data, you can leverage huge datasets to pre-train you models before you train them on the final tasks.
Data2vec is a paper about self-supervision for speech vision and language. The core idea is to use a standard Transformer architecture to predict a latent representations of the data from a masked input. It’s different from usual technique which predict modality-specific targets such as words, visual tokens or unit of speech.
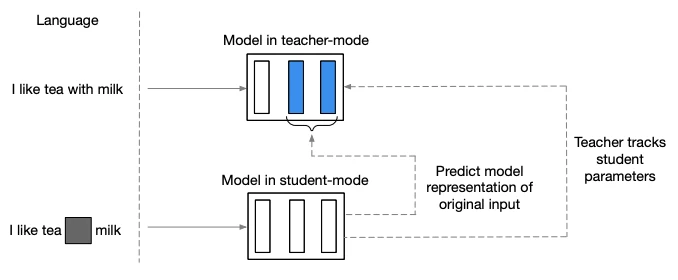
First the model encode a masked version of the training data (student mode). Then training targets are constructed by encoding the unmasked data with the same model but parametrized as an exponentially moving average of the model weights (teacher mode). This idea to use an exponentially moving average of the model weights for the teacher comes from another paper: Emerging Properties in Self-Supervised Vision Transformers. It’a form of self distillation.
It’s great to see more and more work in self-supervision as it unlocks new ways to use data, even when it’s not labelled. Checkout the paper.
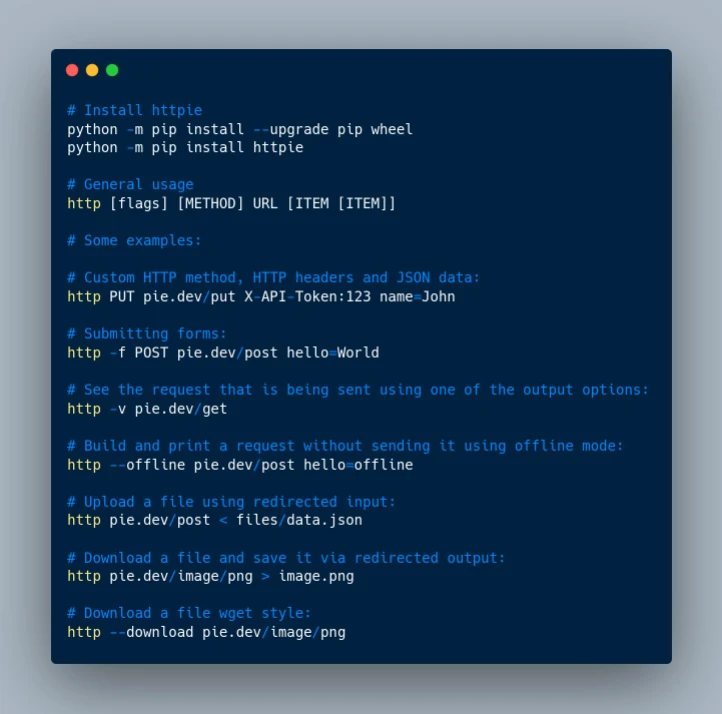
🛠 Tool: HTTPie, Painless API testing and interactions
🤕 Debugging API calls can be tedious. They take time to write, and the results can be difficult to interpret. HTTPie is a delightful CLI HTTP client that makes interacting with web services as human-friendly as possible.
It's perfect for:
👉🏽 Testing
👉🏽 Debugging
👉🏽 Generally getting the most out of APIs and HTTP servers
With the http and https commands, you can easily create and send any sort of HTTP request you need.
📰 News
DeepMind Gato: A Generalist Agent
Inspired by large language models, DeepMind released GATO : a generalist agent. Remarkable features: It handles many types of data: image, text, … The same network with the same weights is used for all the tasks. It uses the context to decide which tasks to complete.
Cloudflare First Database: D1
Cloudflare announced its first database product: D1. It’s a database designed for Cloudflare Workers and built on top of SQLite. It enhances Workers with SQL powers. Along with the other Worker services, we are getting the capabilities to build fully fledged applications.