Bitsletter #2: Le pouvoir de l'apprentissage automatique centré sur les données et les améliorations des mesures Web Vital

🧠 Astuce ML : Suivez une approche centrée sur les données lorsque c'est possible
Il existe deux approches principales pour développer des solutions d'apprentissage automatique :
- Centré sur le modèle : les données sont verrouillées, vous améliorez les modèles pour obtenir de meilleurs résultats
- Centré sur les données : le modèle est verrouillé, vous améliorez les données pour obtenir de meilleurs résultats.
Au fur et à mesure que la recherche progresse, l'état de l'art devient incroyablement bon dans de nombreuses tâches. Développer votre propre modèle, à vos propres frais, apporte des récompenses décroissantes...
Je suis le premier tenté de construire un modèle à partir de zéro, car c'est amusant et éducativement important. Cependant, pour offrir la plus grande valeur, dans le plus court laps de temps, ce n'est pas une bonne approche. Combien de temps a-t-il fallu à des équipes entières pour construire ces modèles SOTA ? Est-il probable que je les batte en peu de temps ? Ai-je les ressources informatiques et suffisamment de données pour entraîner un énorme modèle à partir de zéro ? Réalistement, non (dans de nombreux cas).
Permettons l'introduction d'un autre cadre :
Dans ce cadre, l'accent est mis sur les données. Vous passez beaucoup moins de temps à modéliser et beaucoup plus de temps à nettoyer, étiqueter, collecter et préparer les données. Vous tirez parti des meilleurs modèles disponibles, généralement leur implémentation en open source (dans votre framework préféré), et vous concentrez vos efforts sur la qualité et la quantité des données.
🌐 Astuce Web : Améliorez les mesures vitales du Web avec le chargement paresseux
Les mesures vitales du Web regroupent un ensemble de métriques pour mesurer la qualité de l'expérience utilisateur des applications Web. Les métriques principales sont :
👉🏽 Largest Content Paint (LCP) : mesure la performance de chargement.
👉🏽 Premier délai de saisie (FID) : mesure l'interactivité.
👉🏽 Cumulative Layout Shift (CLS) : mesure la stabilité visuelle.
Une bonne expérience utilisateur se situe en dessous de 2,5 secondes de LCP, 100 ms de FID et 0,1 de CLS : ce sont des chiffres directeurs fournis par Google.
Si vous développez une application Web, vous avez maintenant accès à de nombreux excellentes frameworks JavaScript : React, Vue, Angular, ... et une myriade de bibliothèques JavaScript grâce à npm et aux bundlers de modules.
Mais cela se fait au prix... la taille de votre application augmente.
Vous pourriez penser que les ordinateurs puissants et internet à haut débit atténuent ces problèmes. Pourtant, un nombre important d'utilisateurs se trouvent encore sur des connexions internet lentes comme la 3G et inférieure (par exemple, dans les pays pauvres, ...).
Une solution simple pour contrôler les mesures vitales du Web de votre application est d'utiliser le chargement paresseux. L'idée est simple, vous n'avez pas besoin d'envoyer le code pour afficher les éléments qui se trouvent en dehors du champ de vision de l'application : puisque l'utilisateur ne les voit pas, vous ne devriez pas dépenser de ressources pour eux. Le temps de chargement initial, l'interactivité et la stabilité vont s'améliorer, et pendant que l'utilisateur navigue dans votre application, vous chargez progressivement le code JS requis. Tous les frameworks modernes prennent en charge le chargement paresseux, commencez à l'utiliser pour améliorer l'expérience utilisateur.
👩🔬 Article de recherche : data2vec, un cadre général pour l'apprentissage auto-supervisé en parole, vision et langage
L'apprentissage auto-supervisé est un sujet de recherche important en apprentissage automatique. Yan LeCun, scientifique en chef chez Meta, est convaincu que c'est un élément clé pour améliorer les modèles d'apprentissage profond :
En quelques mots, c'est une sorte d'apprentissage non supervisé où les données elles-mêmes fournissent une supervision. Par exemple, vous pouvez pré-entraîner un modèle de vision par ordinateur sur des images sans étiquette : vous masquez aléatoirement l'image et vous entraînez le modèle à prédire la zone manquante. Ainsi, vous vous attendez à ce que le modèle apprenne une représentation significative des données. Comme il est plus simple de collecter des données non étiquetées, vous pouvez exploiter des ensembles de données énormes pour pré-entraîner vos modèles avant de les entraîner sur les tâches finales.
Data2vec est un document sur l'auto-supervision pour la parole, la vision et le langage. L'idée centrale est d'utiliser une architecture Transformer standard pour prédire une représentation latente des données à partir d'une entrée masquée. C'est différent de la technique habituelle qui prédit des cibles spécifiques à la modalité telles que des mots, des symboles visuels ou des unités de parole.
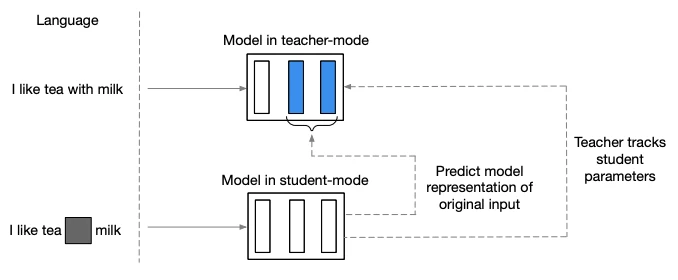
D'abord, le modèle encode une version masquée des données d'entraînement (mode étudiant). Ensuite, les cibles d'entraînement sont construites en encodant les données non masquées avec le même modèle, mais paramétré comme une moyenne mobile exponentielle des poids du modèle (mode enseignant). Cette idée d'utiliser une moyenne mobile exponentielle des poids du modèle pour l'enseignant provient d'un autre document : Emerging Properties in Self-Supervised Vision Transformers. C'est une forme d'auto-distillation.
Il est formidable de voir de plus en plus de travaux dans l'auto-supervision car cela ouvre de nouvelles façons d'utiliser les données, même lorsqu'elles ne sont pas étiquetées. Consultez l'article : lien.
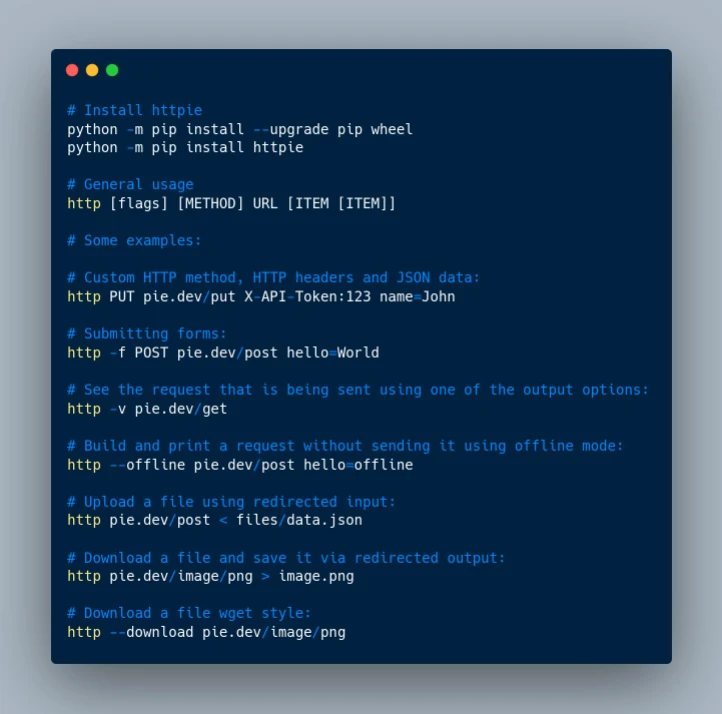
🛠 Outil : HTTPie, tests et interactions d'API sans douleur
🤕 Le débogage des appels API peut être fastidieux. Ils prennent du temps à écrire et les résultats peuvent être difficiles à interpréter. HTTPie est un client HTTP CLI pratique qui rend les interactions avec les services Web aussi conviviales que possible.
Il est parfait pour :
👉🏽 Effectuer des tests
👉🏽 Déboguer
👉🏽 Profiter au maximum des API et des serveurs HTTP
Avec les commandes http et https, vous pouvez facilement créer et envoyer n'importe quel type de requête HTTP dont vous avez besoin.
📰 Nouvelles
DeepMind Gato : un agent généraliste
Inspiré par les grands modèles de langage, DeepMind a publié GATO : un agent généraliste. Ses caractéristiques remarquables : il gère de nombreux types de données : image, texte, ... Le même réseau avec les mêmes poids est utilisé pour toutes les tâches. Il utilise le contexte pour décider quelles tâches accomplir.
Base de données Cloudflare Première : D1
Cloudflare a annoncé son premier produit base de données : D1. Il s'agit d'une base de données conçue pour les Cloudflare Workers et construite sur SQLite. Elle apporte des capacités SQL aux Workers. Avec les autres services Worker, nous avons désormais la possibilité de construire des applications complètes.