Bitsletter #9: The MLOps Journey, Cookie Management, and AI Research Highlights

🧠 ML Tip: Brush up your MLOps skill
Even the most performant model is meaningless if it stays in a notebook ... 💡 Machine learning engineers and data scientists should spend more time on DevOps, especially MLOps (DevOps applied to machine learning). Building a machine learning model is only half the battle. To succeed, the model must be deployed and run efficiently and reliably.
Once you consider all the steps necessary to put machine learning into production, you realize that modeling is just one of them:
🟢 Continuity Machine learning models need continuous processes to remain healthy 👉🏽 Continuous integration: extend test and validation to data and models. 👉🏽 Continuous delivery: automatic deployment of models after training. 👉🏽 Continuous training: automatic retraining of models to maintain performance. 👉🏽 Continuous Monitoring: monitor key business metrics of the deployed model.
🟢 Versioning Reproducibility is a critical component of any machine learning project. To achieve reproducibility, versioning is mandatory, but it goes beyond code: scripts, models, and datasets should all be tracked in a versioning system.
🟢 Experiments tracking Machine learning is inherently a trial-error discipline. This is one of the most crucial factors regarding the final performance of your solution. The more you try, the more likely you will find the best solution. But experiment tracking is not straightforward, it's related to versioning, and you need a robust architecture to take the most out of it.
🟢 Testing There are no reliable systems built without a solid testing process. Machine learning introduces complex dependencies between code and data: you need to test both to guarantee the health of your solution. Data quality checks, unit tests, integration tests, data drift checks, ...
MLOps puts in place processes to create, deploy and monitor models in production. It gives life to our machine learning process and should be highly considered. 📚 MLOps education is essential to be a complete machine learning engineer.
🌐 Web Tip: Reverse proxy to share cookies among services
Cookies are an effective way to manage authentication and authorization. You can quickly implement persisting sessions by storing the id of a logged-in user inside a cookie. Then the browser takes care to send it over every request, minimizing the work client-side.
Moreover, they can be fairly secure if you take setup CORS properly and avoid a few pitfalls: it includes using HTTP-only cookies, secure and signed cookies:
👉🏽 HTTP-only**prevent client-side scripts to access the cookie
👉🏽 Secure**send the cookie only over HTTPS
👉🏽 Signed**sign the cookie so you can verify that it's not altered by a tier
Many web apps have a front-end, and an API served by 2 different services. It would be convenient to share the session cookie between services to unify the authentication and authorization flow. Fortunately, a typical pattern is to have a reverse proxy (Nginx, Caddy, ...) to handle asset compression, HTTPS, rate-liming, ...
If you have both your web app and API behind the reverse proxy (and don't want to use subdomains), you can serve them over different subpaths of your domain:
Application: domain/app/...
API: domain/api/...
By doing so, you will share the cookie between your different services with a straightforward setup. You could even have both API and the web app hosted on the same machine.
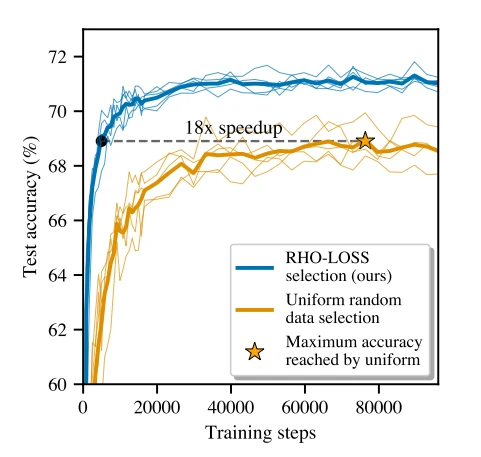
👩🔬 Research Paper: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Data is the fuel of machine learning models and can be hard to gather. Our models can be complex and require a lot of computations, which can be costly in terms of money and environmental impact. Making the best of the data available the fastest possible is crucial for artificial intelligence.
Data selection is a technique that selects the data points on which to train at different training steps. Intuitively, as your model learn, some data points remain harder to learn than others, so it would make sense to spend more time on these tricky samples. Data selection won't select the training samples uniformly for a given training time budget.
This paper introduces a special selection loss: Reducible Holdout Loss Selection (RHO-LOSS). It tries to select points that most reduce the model's generalization loss. Previous online batch selection methods, such as loss or gradient norm selection, try to select points that would minimize the training set loss after training on them. Instead, the technique in this paper tries to select points that minimize the loss on a holdout set.
However, training on all the candidate data points and evaluating the holdout loss each time would be costly. So the authors introduced approximations to find the data points that would better reduce the holdout loss without training on them. They do so by training an auxiliary model (smaller than the main one) exclusively on the holdout set: it saves computation time and allows us to get a good approximation.
The main algorithm is as follows:
- Sample a big batch of data B1
- Use the auxiliary model to sample a smaller batch B2 from B1 with the most promising data points.
- Train the primary model on B2
RHO-LOSS demonstrated compelling benefits:
- Trains in far fewer steps
- Improves accuracy
- Speeds up training on a wide range of datasets, hyperparameters, and architectures
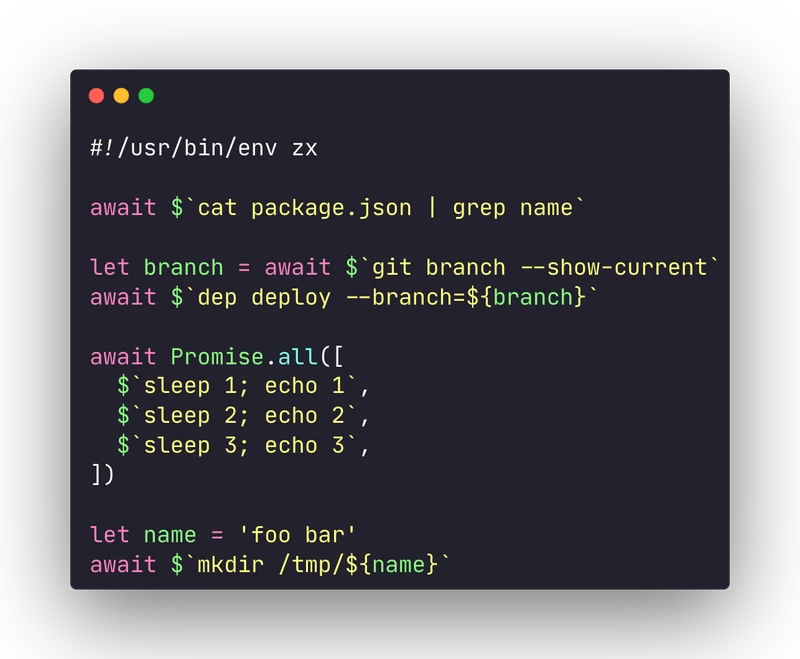
🛠 Tool: Supercharge your shell scripts with JavaScript using FX
😰Tired of unmaintainable and complex Bash scripts? Supercharge your shell with ZX: a powerful JavaScript tool for shell scripting.
We've all been there ... You start writing a simple Bash script, and it grows out of control ... You try to modularize bash code with functions, but it's a pain ... Then you move to other languages to manage your scripts.
JavaScript is an excellent language for writing scripts, but invoking the shell with child processes inside the Node runtime can be tedious. ZX is a library developed by Google which wraps the annoying shell invocation management with a slick library:
👉🏽 Dead simple shell commands invocations
👉🏽 Use async/await to handle asynchronous commands
👉🏽 Wrap groups of commands in an async context
👉🏽 Use every feature of the JavaScript language in your scripts
📰 News
Meta “No Language Left Behind” open source AI now translates 200 languages
Meta released No Language Left Behind, a model capable of translating between 200 languages. It even includes low-resource languages such as Asturian, Luganda, Urdu, and more ...
Bun, the fastest Javascript runtime announced the first beta release
Bundle, transpile, install and run Javascript & Typescript projects with the fastest Javascript runtime! Bun is a new JavaScript runtime with a built-in native bundler, transpiler, task runner, and npm client. It's now in beta. Give it a try.