Bitsletter #9: Le parcours MLOps, Gestion des cookies et Points forts sur la recherche en IA

🧠 Astuce ML : Rehaussez vos compétences en MLOps
Même le modèle le plus performant est insignifiant s'il reste dans un notebook ... 💡 Les ingénieurs en apprentissage automatique et les scientifiques des données devraient passer plus de temps sur le DevOps, en particulier le MLOps (le DevOps appliqué à l'apprentissage automatique). La construction d'un modèle d'apprentissage automatique n'est que la moitié de la bataille. Pour réussir, le modèle doit être déployé et exécuté de manière efficace et fiable.
Une fois que vous avez pris en compte toutes les étapes nécessaires pour mettre l'apprentissage automatique en production, vous réalisez que la modélisation n'en est qu'une parmi elles :
🟢 Continuité Les modèles d'apprentissage automatique nécessitent des processus continus pour rester en bonne santé 👉🏽 Intégration continue : étendre les tests et la validation aux données et aux modèles. 👉🏽 Livraison continue : déploiement automatique des modèles après l'entraînement. 👉🏽 Formation continue : réentrainement automatique des modèles pour maintenir les performances. 👉🏽 Surveillance continue : surveiller les indicateurs clés de performance du modèle déployé.
🟢 Versioning La reproductibilité est un élément essentiel de tout projet d'apprentissage automatique. Pour atteindre la reproductibilité, la mise en version est obligatoire, mais cela va au-delà du code : les scripts, les modèles et les ensembles de données doivent tous être suivis dans un système de mise en version.
🟢 Suivi des expériences L'apprentissage automatique est intrinsèquement une discipline d'essais et d'erreurs. C'est l'un des facteurs les plus cruciaux concernant les performances finales de votre solution. Plus vous essayez, plus vous avez de chances de trouver la meilleure solution. Mais le suivi des expériences n'est pas évident, cela est lié à la mise en version et vous avez besoin d'une architecture solide pour en tirer le meilleur parti.
🟢 Tests Il n'y a pas de systèmes fiables construits sans un solide processus de test. L'apprentissage automatique introduit des dépendances complexes entre le code et les données : vous devez tester les deux pour garantir la santé de votre solution. Contrôles de qualité des données, tests unitaires, tests d'intégration, vérifications de dérive des données, ...
Le MLOps met en place des processus de création, de déploiement et de surveillance des modèles en production. Il donne vie à notre processus d'apprentissage automatique et devrait être largement considéré. 📚 L'éducation MLOps est essentielle pour être un ingénieur en apprentissage automatique complet.
🌐 Astuce Web: Proxy inverse pour partager des cookies entre les services
Les cookies sont un moyen efficace de gérer l'authentification et l'autorisation. Vous pouvez rapidement mettre en place des sessions persistantes en stockant l'identifiant d'un utilisateur connecté dans un cookie. Ensuite, le navigateur se charge de l'envoyer lors de chaque requête, réduisant ainsi le travail côté client.
De plus, ils peuvent être assez sécurisés si vous configurez correctement CORS et évitez quelques pièges : cela inclut l'utilisation de cookies HttpOnly, sécurisés et signés:
👉🏽 HttpOnly**empêche les scripts côté client d'accéder au cookie
👉🏽 Sécurisé**envoie le cookie uniquement via HTTPS
👉🏽 Signé**signe le cookie pour pouvoir vérifier qu'il n'a pas été modifié par un tiers
De nombreuses applications web ont une interface frontale (front-end) et une API servie par 2 services différents. Il serait pratique de partager le cookie de session entre les services pour unifier le flux d'authentification et d'autorisation. Heureusement, un schéma courant est d'avoir un proxy inverse (Nginx, Caddy, ...) pour gérer la compression des ressources, HTTPS, la limitation de débit, ...
Si votre application web et votre API sont tous les deux derrière le proxy inverse (et que vous ne souhaitez pas utiliser de sous-domaines), vous pouvez les servir via différents sous-chemins de votre domaine:
Application: domaine/app/...
API: domaine/api/...
En procédant ainsi, vous allez partager le cookie entre vos différents services avec une configuration simple. Vous pouvez même avoir à la fois l'API et l'application web hébergées sur la même machine.
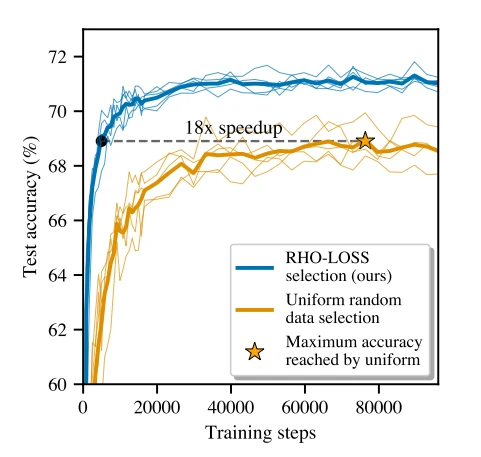
👩🔬 Article de recherche: Formation priorisée sur des points apprenables, digne d'apprentissage et pas encore appris
Les données sont le carburant des modèles d'apprentissage automatique et peuvent être difficiles à rassembler. Nos modèles peuvent être complexes et nécessitent beaucoup de calculs, ce qui peut être coûteux en termes financiers et environnementaux. Tirer le meilleur parti des données disponibles le plus rapidement possible est crucial pour l'intelligence artificielle.
La sélection de données est une technique qui sélectionne les points de données sur lesquels s'entraîner lors des différentes étapes d'apprentissage. Intuitivement, à mesure que votre modèle apprend, certains points de données restent plus difficiles à apprendre que d'autres, il serait donc logique de passer plus de temps sur ces échantillons complexes. La sélection de données ne sélectionne pas uniformément les échantillons d'entraînement pour un budget de temps d'entraînement donné.
Cet article présente une perte de sélection spéciale : Reducible Holdout Loss Selection (RHO-LOSS). Elle tente de sélectionner les points qui réduisent le plus la perte de généralisation du modèle. Les méthodes de sélection de lots en ligne précédentes, telles que la perte ou la norme du gradient, tentent de sélectionner les points qui minimiseraient la perte de l'ensemble d'entraînement après s'être entraînés dessus. Au lieu de cela, la technique de cet article essaie de sélectionner les points qui minimisent la perte sur un ensemble de validation.
Cependant, s'entraîner sur tous les points de données candidats et évaluer la perte de validation à chaque fois serait coûteux. Les auteurs ont donc introduit des approximations pour trouver les points de données qui réduiraient mieux la perte de validation sans s'entraîner sur eux. Ils le font en entraînant un modèle auxiliaire (plus petit que le principal) exclusivement sur l'ensemble de validation : cela permet de gagner du temps de calcul et d'obtenir une bonne approximation.
L'algorithme principal est le suivant :
- Échantillonner un grand lot de données B1
- Utiliser le modèle auxiliaire pour échantillonner un lot plus petit B2 à partir de B1 avec les points de données les plus prometteurs.
- Entraîner le modèle principal sur B2
RHO-LOSS a démontré des avantages convaincants :
- S'entraîne en beaucoup moins d'étapes
- Améliore la précision
- Accélère l'entraînement sur un large éventail de jeux de données, d'hyperparamètres et d'architectures
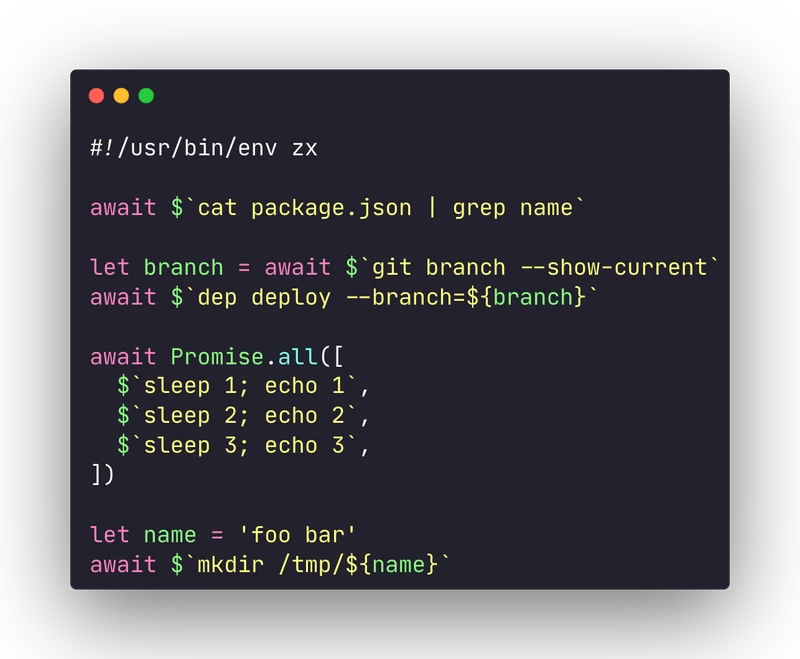
🛠 Outil : Dynamisez vos scripts shell avec JavaScript en utilisant FX
😰 Fatigué des scripts Bash complexes et difficiles à maintenir ? Dynamisez votre shell avec ZX : un puissant outil JavaScript pour les scripts shell.
Nous avons tous connu cela ... Vous commencez à écrire un simple script Bash, et il devient incontrôlable ... Vous essayez de modulariser le code Bash avec des fonctions, mais c'est une douleur ... Ensuite, vous passez à d'autres langages pour gérer vos scripts.
JavaScript est un excellent langage pour écrire des scripts, mais invoquer le shell avec des processus enfants dans l'environnement Node peut être fastidieux. ZX est une bibliothèque développée par Google qui enveloppe la gestion agaçante de l'invocation du shell avec une bibliothèque élégante:
👉🏽 Commandes shell simples à utiliser
👉🏽 Utilise async/await pour gérer les commandes asynchrones
👉🏽 Encadre les groupes de commandes dans un contexte asynchrone
👉🏽 Utilise toutes les fonctionnalités du langage JavaScript dans vos scripts
📰 Actualités
Meta "No Language Left Behind": l'IA open source qui traduit maintenant 200 langues
Meta a publié No Language Left Behind, un modèle capable de traduire entre 200 langues. Cela inclut même des langues à faible ressource telles que Asturian, Luganda, Urdu, et bien d'autres...
Bun, le runtime JavaScript le plus rapide, annonce la première version bêta
Bundle, transpile, installer et exécuter des projets Javascript et Typescript avec le runtime JavaScript le plus rapide ! Bun est un nouveau runtime JavaScript avec un bundler, un transpileur, un gestionnaire de tâches et un client npm native intégrés. Il est maintenant en version bêta. Essayez-le.